
There is a specific moment in this project that I keep coming back to. It was late at night, Sam and I had just finished assembling the last leg, we powered it on for the first time, and the robot stood up. Not perfectly. It wobbled. One joint was slightly miscalibrated and the whole thing leaned to one side. But it stood. After months of CAD files, 3D print failures, simulation runs, and firmware debugging, there was a physical thing in front of us that was trying to stand.
This post is about what that process actually looked like. What we built, how it works, and why we built it this way.
Why a Walking Robot
My interest in this project started with a specific frustration.
Autonomous robotics has been moving fast. Self-driving cars, warehouse robots, drone delivery. But most of what is actually deployed in the world still moves on wheels, and wheels have a hard constraint: they need a flat, continuous surface. The moment there is a step, a curb, or anything uneven, a wheeled robot stops. For a robot to navigate the real world, the way a person or an animal does, it needs legs.
Quadruped robots are genuinely impressive at this. Boston Dynamics' Spot can climb stairs, recover from being kicked, and navigate construction sites. ETH Zürich's ANYmal runs learned locomotion policies that generalize to terrain the robot has never seen before. These systems work, and they work largely because of reinforcement learning.
The problem is that almost none of it is accessible. The robots are expensive and closed. The research is published but the implementations stay proprietary. What actually exists in the open-source world for quadrupeds is mostly kinematic gait controllers, hand-designed stepping patterns based on classical robotics, where an engineer explicitly programs the leg trajectories rather than letting the robot learn them. That works, and there is real engineering involved in doing it well, but it has a ceiling. A hand-designed gait that works on flat ground does not automatically transfer to stairs or rough terrain. A learned policy can.
The gap between where the research is and what is open and reproducible is what motivated this project. The goal is a fully open-source quadruped with ML-based locomotion at its core, documented well enough that someone starting from scratch can follow every step from hardware to software.
What is Reinforcement Learning
Before getting into how we trained the walking policy, it helps to understand what reinforcement learning actually is, because it gets described in ways that make it sound either trivial or magical depending on who is writing about it.
The core idea is that an agent learns by interacting with an environment. At each step it receives an observation, takes an action, and receives a reward signal that tells it how well it did. It has no explicit instructions about how to do anything. It just tries things, sees what happens, and gradually figures out which actions lead to better outcomes.
The classic analogy is training a dog. You do not hand the dog a textbook on the biomechanics of sitting. You reward the behavior you want and ignore everything else. The dog, motivated by treats, gradually learns the association. Reinforcement learning works the same way, except the agent is a neural network, the treats are scalar numbers, and the training runs for tens of millions of iterations over a few hours on a GPU.
For a walking robot the setup is as follows. The agent is the neural network controller. The observation is everything the robot can sense about itself and its surroundings. The actions are the joint angle targets sent to each of the twelve motors. The reward is a function we design to encode what we want the robot to do. If we design it well, the policy learns to walk. If we design it poorly, it learns to do something technically optimal that completely misses the point, a problem called reward hacking that shows up more often than you would expect.
Key RL Concepts Worth Knowing
A few terms appear constantly in this area and are worth building intuition for.
The policy is the learned mapping from observations to actions. It is the brain of the robot. At the start of training it is essentially random. Over millions of training steps it becomes the function that keeps the robot upright and moving in the right direction. Once training is done the policy is frozen and deployed to run at 50 Hz on the real hardware.
The observation space is everything the robot is allowed to see at each step. We use 45 numbers: angular velocity from the IMU, the gravity direction in the robot's body frame, the velocity commands telling it where to go, the position and velocity of all twelve joints, and the action the policy output on the previous step. That last one gives the network a short memory of what it just did, which turns out to matter for generating smooth motion rather than jerky independent steps.
The action space is what the robot can control. At each timestep the policy outputs twelve numbers, one target angle per motor. There is no explicit concept of a step, a stride, or a gait phase in the policy at all. Those patterns emerge from training.
The reward function is the most important design decision in the whole system. We reward forward velocity toward the target speed, penalize the robot tilting past a threshold, penalize energy waste, and add a small survival bonus for staying upright each timestep. The survival bonus is especially important early in training when the robot cannot yet walk and needs some gradient to follow.
The actor-critic architecture trains two networks together. The actor decides what action to take. The critic estimates how good the current situation is, not to control the robot, but to give the actor better feedback during training. Only the actor runs on the deployed robot. The critic exists only during training.
Training in Simulation First
Running training directly on a real robot is impractical. A single run needs tens of millions of environment steps to converge. At 50 Hz on real hardware, accounting for resets and everything else, that would take months of continuous operation. The robot would destroy itself thousands of times. Physics does not pause and restart.
Simulation solves all of that. In a physics simulator you can run thousands of parallel environments simultaneously, each one physically independent. Falls are free. Resets are instant. What takes months in reality takes hours on a GPU.
We used Genesis as our simulator. It is a modern, GPU-accelerated physics engine built around Python with native PyTorch integration. The robot's URDF file, which describes its geometry, mass distribution, joint limits, and collision shapes, goes in and Genesis handles all the contact physics, joint dynamics, and rigid body simulation. On a single RTX 4060 we run 4096 parallel environments.
The sim-to-real gap is the central challenge of this approach. Simulation is always a simplification of reality. Real servo motors have backlash, friction, and latency that no simulator perfectly captures. The floor is not a flat plane. Sensors have noise. A policy trained in clean simulation conditions will behave differently when it meets the physical world.
Domain randomization is the standard mitigation. During training we randomize joint stiffness, motor delays, ground friction, and body mass within reasonable bounds across the population of parallel environments. The policy learns to cope with variation rather than overfitting to conditions being exactly right.
The Hardware: Designing and Printing the Robot
The mechanical design starts from SpotMicro, an open-source quadruped inspired by Boston Dynamics' Spot. It has twelve degrees of freedom, three per leg. A hip joint handles lateral abduction. An upper leg joint and lower leg joint together control reach and ground clearance. That kinematic structure directly mirrors the simulation model.
We adapted the design for our motor selection and physical constraints. All structural parts are 3D printed. This takes its own iteration cycle. The first set of leg parts did not fit the servo horns tightly enough. The second set was too tight. The third worked. This is just how hardware development goes and 3D printing makes it cheap.
The electronics board handles power distribution, servo signaling, and the onboard computer. A BNO055 IMU provides orientation and angular velocity at 50 Hz. That sensor is critical for the policy since the observation vector includes angular velocity and the gravity direction in the robot's body frame, both of which come from the IMU directly. Without clean IMU data the observation is corrupted and the policy fails.
We're also integrating an RPLidar on top of the body. It sweeps 360 degrees and returns distance measurements at around 8000 samples per second. That data feeds the SLAM and navigation stack, building the map the robot uses to understand its environment.
Training the Locomotion Policy
The 45-number observation vector the policy sees at each 20ms step is structured carefully to match exactly what was available during training. Angular velocity from the gyroscope, scaled down so the values stay in a range the network handles well. Gravity direction from the orientation quaternion. Three velocity commands. Twelve joint position offsets from the neutral standing pose. Twelve joint velocities. And the twelve raw actions from the previous step.
Every scale factor matters. If the policy was trained with joint velocities multiplied by 0.05 to keep them near unit range, then at deployment those velocities must also be multiplied by 0.05 before going into the network. A mismatch anywhere in the observation shifts the input distribution out of the range the policy was trained on and the behavior degrades immediately. This is one of the subtle sources of sim-to-real problems that does not always get enough attention.
Training runs with PPO, a policy gradient algorithm well-suited to continuous control. We ran it in Genesis with 4096 parallel environments. Watching a training run start from scratch is instructive. For the first few hundred iterations the robot just collapses immediately. Then it starts staying upright for a moment. Then longer. Around a thousand iterations it starts taking steps, not useful ones, but steps. By convergence it has a stable trot gait that responds to velocity commands.
Alongside the RL policy, we also implemented a kinematic trot gait as a baseline. This uses closed-form inverse kinematics to compute joint angles for a hand-designed stepping pattern with no learning at all. Two diagonal leg pairs alternate in a standard trot rhythm. It is useful for verifying hardware behavior without needing a trained policy.
The reason we have both is exactly the point this project is trying to make. The kinematic gait works. It is predictable and debuggable. But it is a ceiling. The RL policy is harder to train and harder to debug, but it learns behaviors that generalize in ways no hand-coded gait can, because it was trained on a distribution of conditions rather than a single set of assumptions about the world.
Results and What is Next
The robot walks. Both controllers produce stable locomotion on flat ground. Forward walking is solid. Turning is functional but noisier than we want, and uneven terrain still degrades the RL policy more than it should. Those are the next things to improve through better training curriculum and more domain randomization.
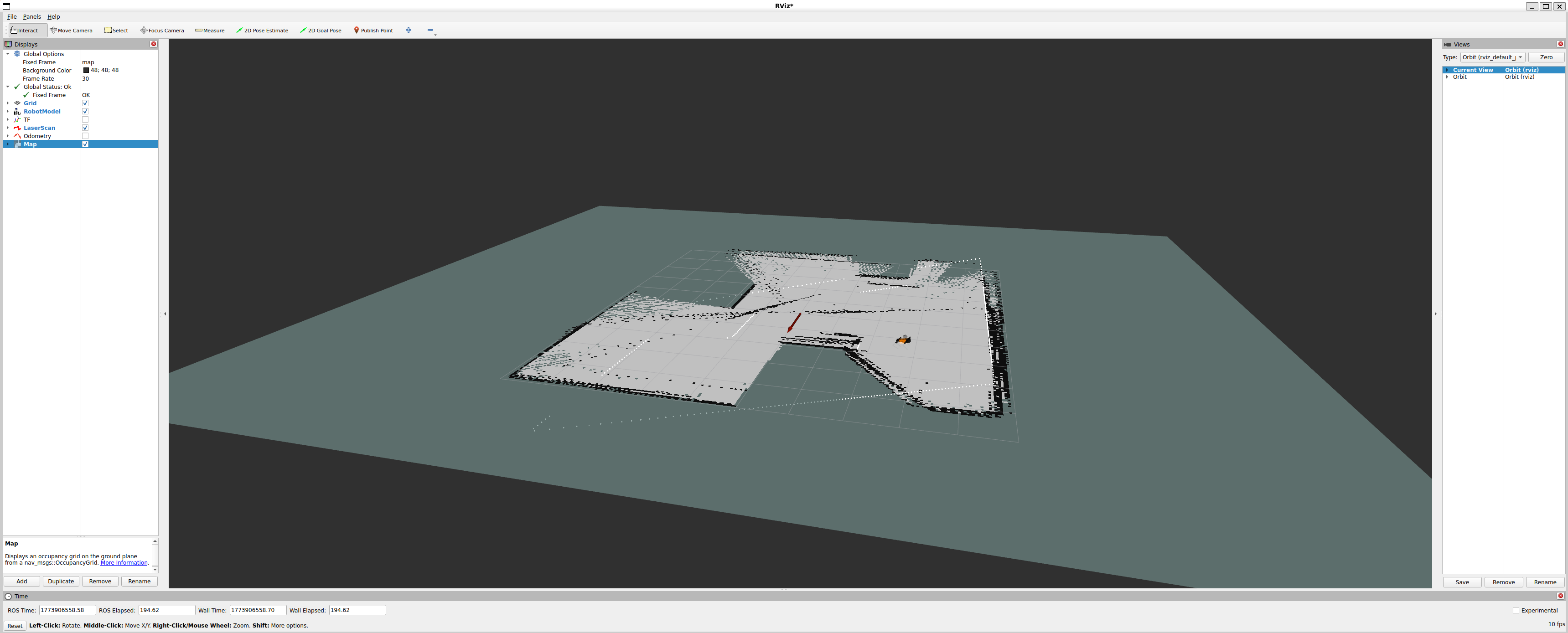
On the software side, the full ROS 2 stack is running. The LiDAR SLAM pipeline builds a real-time occupancy map as the robot explores. Nav2 handles global path planning and local obstacle avoidance. The velocity commands it generates feed directly into whichever gait controller is active, which then drives the servos.
The next milestone is fully autonomous waypoint navigation. Give the robot a list of positions in the map, have it navigate between them without human input, and handle unexpected obstacles along the way. That is the point where locomotion, sensing, mapping, and planning all come together into something that does a complete useful task end to end.
The longer goal is a robot that can follow its owner through a real building, step over thresholds, handle doorways, and recover from the kinds of disturbances that real environments produce. That requires better sim-to-real transfer, a more robust locomotion policy, and probably a second round of training with harder domain randomization.
Everything will be open sourced. CAD files, training code, ROS 2 nodes, hardware assembly guide, and documentation at every step. The gap between closed research and accessible implementation is exactly what motivated this project, and closing that gap is part of the point. If this interests you, reach out or follow along on the repository.